
Resin Documentationhome company docs
app server 
app server
resin clustering
Resin's HTTP Web Server includes load balancing for scalability and reliability.
Resin Professional includes a LoadBalanceServlet that can balance requests to backend servers. Because it is implemented as a servlet, this configuration is the most flexible. A site might use 192.168.0.1 as the frontend load balancer, and send all requests for /foo to the backend host 192.168.0.10 and all requests to /bar to the backend host 192.168.0.11. Since Resin has an integrated HTTP proxy cache, the web-tier machine can cache results for the backend servers. Load balancing divides the Resin servers into two clusters: the web-tier and the app-tier. In Resin 3.1, all the cluster and load balance configuration is in a single resin.conf. The actual deployed server is selected with the command-line argument. Using Resin as the load balancing web server requires a minimum of two configuration files: one for the load balancing server, and one for the backend servers. The front configuration will dispatch to the backend servers, while the backend will actually serve the requests. The web-tier server does the load balancingIn the following example, there are three servers and two conf files. The first server (192.168.0.1), which uses web-tier.conf, is the load balancer. It has an <http> listener, it receives requests from browsers, and dispatches them to the backend servers (192.168.0.10 and 192.168.0.11). resin.conf
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="web-tier">
<server-default>
<http port="80"/>
</serve-default>
<server id="web-a" address="192.168.0.1"/>
<server id="web-b" address="192.168.0.1"/>
<cache disk-size="1024M" memory-size="256M"/>
<host id="">
<web-app id="/">
<!-- balance all requests to cluster app-tier -->
<rewrite-dispatch>
<load-balance regexp="" cluster="app-tier"/>
</rewrite-dispatch>
</web-app>
</host>
</cluster>
<cluster id="app-tier">
<server id="app-a" address="192.168.0.10" port="6800"/>
<server id="app-b" address="192.168.0.11" port="6800"/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
<web-app-default>
<session-config>
<use-persistent-store/>
</session-config>
</web-app-default>
<host id="www.foo.com">
...
</host>
</cluster>
</resin>
The LoadBalanceServlet selects a backend server using a round-robin policy. Although the round-robin policy is simple, in practice it is as effective as complicated balancing policies. In addition, because it's simple, round-robin is more robust and faster than adaptive policies. The backend server respond to the requestsA seperate conf file is used to configure all of the backend servers.
In this case, there are two backend servers, both configured in the conf file
Sites using sessions will configure distributed sessions to make sure the users see the same session values. Starting the serversStarting each server 192.168.0.1> java lib/resin.jar -server web-a start 192.168.0.2> java lib/resin.jar -server web-b start 192.168.0.10> java lib/resin.jar -server app-a start 192.168.0.11> java lib/resin.jar -server app-b start In most cases, the web-tier will dispatch everything to the app-tier servers. Because of Resin's proxy cache, the web-tier servers will serve static pages as fast as if they were local pages. In some cases, though, it may be important to send different requests to different backend clusters. The <load-balance> tag can choose clusters based on URL patterns. The following <rewrite-dispatch> keeps all *.png, *.gif, and *.jpg files on the web-tier, sends everything in /foo/* to the foo-tier cluster, everything in /bar/* to the bar-tier cluster, and keeps anything else on the web-tier. split dispatching
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="web-tier">
<server id="web-a">
<http port="80"/>
</server>
<cache memory-size="64m"/>
<host id="">
<web-app id="/">
<rewrite-dispatch>
<dispatch regexp="(\.png|\.gif|\.jpg)"/>
<load-balance regexp="^/foo" cluster="foo-tier"/>
<load-balance regexp="^/bar" cluster="bar-tier"/>
</rewrite-dispatch>
</web-app>
</host>
</cluster>
<cluster id="foo-tier">
...
</cluster>
<cluster id="bar-tier">
...
</cluster>
</resin>
A session needs to stay on the same JVM that started it. Otherwise, each JVM would only see every second or third request and get confused. To make sure that sessions stay on the same JVM, Resin encodes the cookie with the host number. In the previous example, the hosts would generate cookies like:
On the web-tier, Resin will decode the cookie and send it to the appropriate host. So would go to app-b. In the infrequent case that app-b fails, Resin will send the request to app-a. The user might lose the session but that's a minor problem compared to showing a connection failure error. To save sessions, you'll need to use distributed sessions. Also take a look at tcp sessions. The following example is a typical configuration for a distributed server using an external hardware load-balancer, i.e. where each Resin is acting as the HTTP server. Each server will be started as or to grab its specific configuration. In this example, sessions will only be stored when the server shuts down, either for maintenance or with a new version of the server. This is the most lightweight configuration, and doesn't affect performance significantly. If the hardware or the JVM crashes, however, the sessions will be lost. (If you want to save sessions for hardware or JVM crashes, remove the <save-only-on-shutdown/> flag.) resin.conf
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server-default>
<http port='80'/>
</server-default>
<server id='app-a' address='192.168.0.1'/>
<server id='app-b' address='192.168.0.2'/>
<server id='app-c' address='192.168.0.3'/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
<web-app-default>
<!-- enable tcp-store for all hosts/web-apps -->
<session-config>
<use-persistent-store/>
<save-only-on-shutdown/>
</session-config>
</web-app-default>
...
</cluster>
</resin>
Requests can be made to specific servers in the app-tier. The web-tier uses the value of the jsessionid to maintain sticky sessions. You can include an explicit jsessionid to force the web-tier to use a particular server in the app-tier. Resin uses the first character of the jsessionid to identify the backend server to use, starting with `a' as the first backend server. If wwww.example.com resolves to your web-tier, then you can use:
Configuration for persistent store uses the persistent-store tag.
Persistent sessions are configured in the . File-based sessions use .
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<file-store>WEB-INF/sessions</file-store>
</session-config>
</web-app>
Sessions are stored as files in the directory. When the session changes, the updates will be written to the file. After Resin loads an Application, it will load the stored sessions. File-based persistence is not useful in multi-server environments. Although a network filesystem such as NFS will allow all the servers to access the same filesystem, it's not designed for the fine-grained access. For example, NFS will cache pages. So if one server modifies the page, e.g. a session value, the other servers may not see the change for several seconds. Distributed sessions are intrinsically more complicated than single-server sessions. Single-server session can be implemented as a simple memory-based Hashtable. Distributed sessions must communicate between machines to ensure the session state remains consistent. Load balancing with multiple machines either uses or . Sticky sessions put more intelligence on the load balancer, and symmetrical sessions puts more intelligence on the JVMs. The choice of which to use depends on what kind of hardware you have, how many machines you're using and how you use sessions. Distributed sessions can use a database as a backing store, or they can distribute the backup among all the servers using TCP. Symmetrical SessionsSymmetrical sessions happen with dumb load balancers like DNS round-robin. A single session may bounce from machine A to machine B and back to machine B. For JDBC sessions, the symmetrical session case needs the attribute described below. Each request must load the most up-to-date version of the session. Distributed sessions in a symmetrical environment are required to make sessions work at all. Otherwise the state will end up spread across the JVMs. However, because each request must update its session information, it is less efficient than sticky sessions. Sticky SessionsSticky sessions require more intelligence on the load-balancer, but are easier for the JVM. Once a session starts, the load-balancer will always send it to the same JVM. Resin's load balancing, for example, encodes the session id as 'aaaXXX' and 'baaXXX'. The 'aaa' session will always go to JVM-a and 'baa' will always go to JVM-b. Distributed sessions with a sticky session environment add reliability. If JVM-a goes down, JVM-b can pick up the session without the user noticing any change. In addition, distributed sticky sessions are more efficient. The distributor only needs to update sessions when they change. So if you update the session once when the user logs in, the distributed sessions can be very efficient. always-load-sessionSymmetrical sessions must use the 'always-load-session' flag to update each session data on each request. always-load-session is only needed for jdbc-store sessions. tcp-store sessions use a more-sophisticated protocol that eliminates the need for always-load-session, so tcp-store ignores the always-load-session flag. The attribute forces sessions to check the store for each request. By default, sessions are only loaded from persistent store when they are created. In a configuration with multiple symmetric web servers, sessions can be loaded on each request to ensure consistency. always-save-sessionBy default, Resin only saves session data when you add new values to the session object, i.e. if the request calls . This may be insufficient when storing large objects. For example, if you change an internal field of a large object, Resin will not automatically detect that change and will not save the session object. With Resin will always write the session to the store at the end of each request. Although this is less efficient, it guarantees that updates will get stored in the backup after each request. Database backed sessions are the easiest to understand. Session data gets serialized and stored in a database. The data is loaded on the next request. For efficiency, the owning JVM keeps a cache of the session value, so it only needs to query the database when the session changes. If another JVM stores a new session value, it will notify the owner of the change so the owner can update its cache. Because of this notification, the database store is cluster-aware. In some cases, the database can become a bottleneck. By adding load to an already-loaded system, you may harm performance. One way around that bottleneck is to use a small, quick database like MySQL for your session store and save the "Big Iron" database like Oracle for your core database needs. The database must be specified using a . The database store will automatically create a table. The JDBC store needs to know about the other servers in the cluster in order to efficiently update them when changes occur to the server. JDBC store
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server-default>
<http port="80"/>
</server-default>
<server id="app-a" address="192.168.2.10" port="6800"/>
<server id="app-b" address="192.168.2.11" port="6800"/>
<database jndi-name="jdbc/session">
...
</database>
<persistent-store type="jdbc">
<init>
<data-source>jdbc/session<data-source>
</init>
</persistent-store>
...
<web-app-default>
<session-config>
<use-persistent-store/>
</session-config>
</web-app-default>
...
</cluster>
</resin>
The persistent store is configured in the <server> with persistent-store. Each web-app which needs distributed sessions must enable the persistent store with a use-persistent-store tag in the session-config.
CREATE TABLE persistent_session ( id VARCHAR(64) NOT NULL, data BLOB, access_time int(11), expire_interval int(11), PRIMARY KEY(id) ) The store is enabled with <use-persistent-store> in the session config.
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<use-persistent-store/>
<always-save-session/>
</session-config>
</web-app>
The distributed cluster stores the sessions across the cluster servers. In some configurations, the cluster store may be more efficient than the database store, in others the database store will be more efficient. With cluster sessions, each session has an owning JVM and a backup JVM. The session is always stored in both the owning JVM and the backup JVM. The cluster store is configured in the in the <cluster>. It uses the <server> hosts in the <cluster> to distribute the sessions. The session store is enabled in the <session-config> with the <use-persistent-store>.
<resin xmlns="http://caucho.com/ns/resin">
...
<cluster id="app-tier">
<server id="app-a" host="192.168.0.1" port="6802"/>
<server id="app-b" host="192.168.0.2" port="6802"/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
...
</cluster>
</resin>
The configuration is enabled in the .
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<use-persistent-store="true"/>
</session-config>
</web-app>
The <srun> and <srun-backup> hosts are treated as a cluster of hosts. Each host uses the other hosts as a backup. When the session changes, the updates will be sent to the backup host. When the host starts, it looks up old sessions in the other hosts to update its own version of the persistent store. Symmetric load-balanced servers
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server-default>
<http port='80'/>
</server-default>
<server id="app-a" address="192.168.2.10" port="6802"/>
<server id="app-b" address="192.168.2.11" port="6803"/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
<host id=''>
<web-app id=''>
<session-config>
<use-persistent-store="true"/>
</session-config>
</web-app>
</host>
</cluster>
</resin>
Resin's cluster protocol for distributed sessions can is an alternative to JDBC-based distributed sessions. In some configurations, the cluster-stored sessions will be more efficient than JDBC-based sessions. Because sessions are always duplicated on separate servers, cluster sessions do not have a single point of failure. As the number of servers increases, JDBC-based sessions can start overloading the backing database. With clustered sessions, each additional server shares the backup load, so the main scalability issue reduces to network bandwidth. Like the JDBC-based sessions, the cluster store sessions uses sticky-session caching to avoid unnecessary network traffic. The cluster configuration must tell each host the servers in the cluster and it must enable the persistent in the session configuration with use-persistent-store. Because session configuration is specific to a virtual host and a web-application, each web-app needs enabled individually. The web-app-default tag can be used to enable distributed sessions across an entire site. Most sites using Resin's load balancing will already have the cluster configured. Each block corresponds to a host, including the current host. Since cluster sessions uses Resin's srun protocol, each host must listen for srun requests. resin.conf fragment
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server id="app-a" host="192.168.0.1"/>
<server id="app-b" host="192.168.0.2"/>
<server id="app-c" host="192.168.0.3"/>
<server id="app-d" host="192.168.0.4"/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
...
<host id="">
<web-app id='myapp'>
...
<session-config>
<use-persistent-store/>
</session-config>
</web-app>
</host>
</cluster>
</resin>
Usually, hosts will share the same resin.conf. Each host will be started with a different to select the correct block. On Unix, startup will look like: Starting Host C on Unix resin-3.0.x> bin/httpd.sh -conf conf/resin.conf -server c start On Windows, Resin will generally be configured as a service: Starting Host C on Windows resin-3.0.x> bin/httpd -conf conf/resin.conf -server c -install-as ResinC always-save-sessionResin's distributed sessions needs to know when a session has changed in order to save the new session value. Although Resin can detect when an application calls , it can't tell if an internal session value has changed. The following Counter class shows the issue: Counter.java
package test;
public class Counter implements java.io.Serializable {
private int _count;
public int nextCount() { return _count++; }
}
Assuming a copy of the Counter is saved as a session attribute, Resin doesn't know if the application has called . If it can't detect a change, Resin will not backup the new session, unless is set. When is true, Resin will back up the session on every request. ... <web-app id="/foo"> ... <session-config> <use-persistent-store/> <always-save-session/> </session-config> ... </web-app> Like the JDBC-based sessions, Resin will ignore the flag for cluster sessions. Because the cluster protocol notifies servers of changes, is not needed. SerializationResin's distributed sessions relies on Java serialization to save and restore sessions. Application object must for distributed sessions to work. Session RequestTo see how cluster sessions work, consider a case where the load balancer sends the request to a random host. Host C owns the session but the load balancer gives the request to Host A. In the following figure, the request modifies the session so it must be saved as well as loaded. 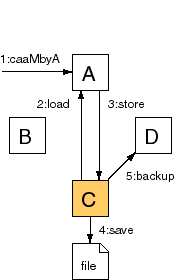 The session id encodes the owning host. The example session id, , decodes to an srun-index of 3, mapping to Host C. Resin determines the backup host from the cookie as well. Host A must know the owning host for every cookie so it can communicate with the owning srun. The example configuration defines all the sruns Host A needs to know about. If Host C is unavailable, Host A can use its configuration knowledge to use Host D as a backup for instead.. When the request first accesses the session, Host A asks Host C for the serialized session data (). Since Host A doesn't cache the session data, it must ask Host C for an update on each request. For requests that only read the session, this TCP load is the only extra overhead, i.e. they can skip . The flag, in contrast, will always force a write. At the end of the request, Host A writes any session updates to Host C (). If always-save-session is false and the session doesn't change, this step can be skipped. Host A sends the new serialized session contents to Host C. Host C saves the session on its local disk () and saves a backup to Host D (). Sticky Session RequestSmart load balancers that implement sticky sessions can improve cluster performance. In the previous request, Resin's cluster sessions maintain consistency for dumb load balancers or twisted clients like the AOL browsers. The cost is the additional network traffic for and . Smart load-balancers can avoid the network traffic of and . 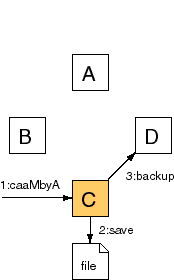 Host C decodes the session id, . Since it owns the session, Host C gives the session to the servlet with no work and no network traffic. For a read-only request, there's zero overhead for cluster sessions. So even a semi-intelligent load balancer will gain a performance advantage. Normal browsers will have zero overhead, and bogus AOL browsers will have the non-sticky session overhead. A session write saves the new serialized session to disk () and to Host D (). will determine if Resin can take advantage of read-only sessions or must save the session on each request. Disk copyResin stores a disk copy of the session information, in the location specified by the . The disk copy serves two purposes. The first is that it allows Resin to keep session information for a large number of sessions. An efficient memory cache keeps the most active sessions in memory and the disk holds all of the sessions without requiring large amounts of memory. The second purpose of the disk copy is that the sessions are recovered from disk when the server is restarted. FailoverSince the session always has a current copy on two servers, the load balancer can direct requests to the next server in the ring. The backup server is always ready to take control. The failover will succeed even for dumb load balancers, as in the non-sticky-session case, because the srun hosts will use the backup as the new owning server. In the example, either Host C or Host D can stop and the sessions will use the backup. Of course, the failover will work for scheduled downtime as well as server crashes. A site could upgrade one server at a time with no observable downtime. RecoveryWhen Host C restarts, possibly with an upgraded version of Resin, it needs to use the most up-to-date version of the session; its file-saved session will probably be obsolete. When a "new" session arrives, Host C loads the saved session from both the file and from Host D. It will use the newest session as the current value. Once it's loaded the "new" session, it will remain consistent as if the server had never stopped. No Distributed LockingResin's cluster sessions does not lock sessions. For browser-based sessions, only one request will execute at a time. Since browser sessions have no concurrently, there's no need for distributed locking. However, it's a good idea to be aware of the lack of distributed locking. Configuration for persistent store uses the persistent-store tag.
Persistent sessions are configured in the . File-based sessions use .
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<file-store>WEB-INF/sessions</file-store>
</session-config>
</web-app>
Sessions are stored as files in the directory. When the session changes, the updates will be written to the file. After Resin loads an Application, it will load the stored sessions. File-based persistence is not useful in multi-server environments. Although a network filesystem such as NFS will allow all the servers to access the same filesystem, it's not designed for the fine-grained access. For example, NFS will cache pages. So if one server modifies the page, e.g. a session value, the other servers may not see the change for several seconds. Distributed sessions are intrinsically more complicated than single-server sessions. Single-server session can be implemented as a simple memory-based Hashtable. Distributed sessions must communicate between machines to ensure the session state remains consistent. Load balancing with multiple machines either uses or . Sticky sessions put more intelligence on the load balancer, and symmetrical sessions puts more intelligence on the JVMs. The choice of which to use depends on what kind of hardware you have, how many machines you're using and how you use sessions. Distributed sessions can use a database as a backing store, or they can distribute the backup among all the servers using TCP. Symmetrical SessionsSymmetrical sessions happen with dumb load balancers like DNS round-robin. A single session may bounce from machine A to machine B and back to machine B. For JDBC sessions, the symmetrical session case needs the attribute described below. Each request must load the most up-to-date version of the session. Distributed sessions in a symmetrical environment are required to make sessions work at all. Otherwise the state will end up spread across the JVMs. However, because each request must update its session information, it is less efficient than sticky sessions. Sticky SessionsSticky sessions require more intelligence on the load-balancer, but are easier for the JVM. Once a session starts, the load-balancer will always send it to the same JVM. Resin's load balancing, for example, encodes the session id as 'aaaXXX' and 'baaXXX'. The 'aaa' session will always go to JVM-a and 'baa' will always go to JVM-b. Distributed sessions with a sticky session environment add reliability. If JVM-a goes down, JVM-b can pick up the session without the user noticing any change. In addition, distributed sticky sessions are more efficient. The distributor only needs to update sessions when they change. So if you update the session once when the user logs in, the distributed sessions can be very efficient. always-load-sessionSymmetrical sessions must use the 'always-load-session' flag to update each session data on each request. always-load-session is only needed for jdbc-store sessions. tcp-store sessions use a more-sophisticated protocol that eliminates the need for always-load-session, so tcp-store ignores the always-load-session flag. The attribute forces sessions to check the store for each request. By default, sessions are only loaded from persistent store when they are created. In a configuration with multiple symmetric web servers, sessions can be loaded on each request to ensure consistency. always-save-sessionBy default, Resin only saves session data when you add new values to the session object, i.e. if the request calls . This may be insufficient when storing large objects. For example, if you change an internal field of a large object, Resin will not automatically detect that change and will not save the session object. With Resin will always write the session to the store at the end of each request. Although this is less efficient, it guarantees that updates will get stored in the backup after each request. Database backed sessions are the easiest to understand. Session data gets serialized and stored in a database. The data is loaded on the next request. For efficiency, the owning JVM keeps a cache of the session value, so it only needs to query the database when the session changes. If another JVM stores a new session value, it will notify the owner of the change so the owner can update its cache. Because of this notification, the database store is cluster-aware. In some cases, the database can become a bottleneck. By adding load to an already-loaded system, you may harm performance. One way around that bottleneck is to use a small, quick database like MySQL for your session store and save the "Big Iron" database like Oracle for your core database needs. The database must be specified using a . The database store will automatically create a table. The JDBC store needs to know about the other servers in the cluster in order to efficiently update them when changes occur to the server. JDBC store
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server-default>
<http port="80"/>
</server-default>
<server id="app-a" address="192.168.2.10" port="6800"/>
<server id="app-b" address="192.168.2.11" port="6800"/>
<database jndi-name="jdbc/session">
...
</database>
<persistent-store type="jdbc">
<init>
<data-source>jdbc/session<data-source>
</init>
</persistent-store>
...
<web-app-default>
<session-config>
<use-persistent-store/>
</session-config>
</web-app-default>
...
</cluster>
</resin>
The persistent store is configured in the <server> with persistent-store. Each web-app which needs distributed sessions must enable the persistent store with a use-persistent-store tag in the session-config.
CREATE TABLE persistent_session ( id VARCHAR(64) NOT NULL, data BLOB, access_time int(11), expire_interval int(11), PRIMARY KEY(id) ) The store is enabled with <use-persistent-store> in the session config.
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<use-persistent-store/>
<always-save-session/>
</session-config>
</web-app>
The distributed cluster stores the sessions across the cluster servers. In some configurations, the cluster store may be more efficient than the database store, in others the database store will be more efficient. With cluster sessions, each session has an owning JVM and a backup JVM. The session is always stored in both the owning JVM and the backup JVM. The cluster store is configured in the in the <cluster>. It uses the <server> hosts in the <cluster> to distribute the sessions. The session store is enabled in the <session-config> with the <use-persistent-store>.
<resin xmlns="http://caucho.com/ns/resin">
...
<cluster id="app-tier">
<server id="app-a" host="192.168.0.1" port="6802"/>
<server id="app-b" host="192.168.0.2" port="6802"/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
...
</cluster>
</resin>
The configuration is enabled in the .
<web-app xmlns="http://caucho.com/ns/resin">
<session-config>
<use-persistent-store="true"/>
</session-config>
</web-app>
The <srun> and <srun-backup> hosts are treated as a cluster of hosts. Each host uses the other hosts as a backup. When the session changes, the updates will be sent to the backup host. When the host starts, it looks up old sessions in the other hosts to update its own version of the persistent store. Symmetric load-balanced servers
<resin xmlns="http://caucho.com/ns/resin">
<cluster id="app-tier">
<server-default>
<http port='80'/>
</server-default>
<server id="app-a" address="192.168.2.10" port="6802"/>
<server id="app-b" address="192.168.2.11" port="6803"/>
<persistent-store type="cluster">
<init path="cluster"/>
</persistent-store>
<host id=''>
<web-app id=''>
<session-config>
<use-persistent-store="true"/>
</session-config>
</web-app>
</host>
</cluster>
</resin>
|